Edge AI vs Cloud AI: Which Architecture Fits Your Latency Budget?
By NanoSchool Editorial Team · Published 29 April 2025 · 7 min read
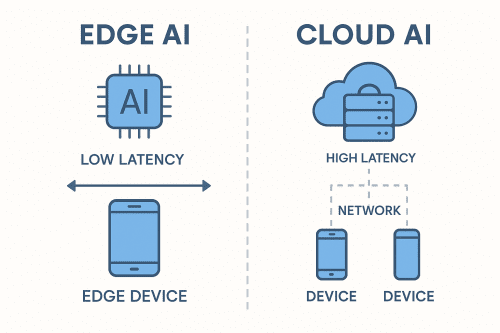
What Is Edge AI?
Edge AI runs ML inference on-device—Raspberry Pi cameras, NVIDIA Jetson gateways or wearable ECG patches. Models are quantised, pruned and compiled to fit CPU, GPU and power budgets for uninterrupted real-time decisions.
What Is Cloud AI?
Cloud AI centralises compute in data centres. Data travels to the cloud for processing on GPUs/TPUs. While scalable, it adds network latency and may raise data-sovereignty concerns.
Edge AI vs Cloud AI: The Four-Factor Test
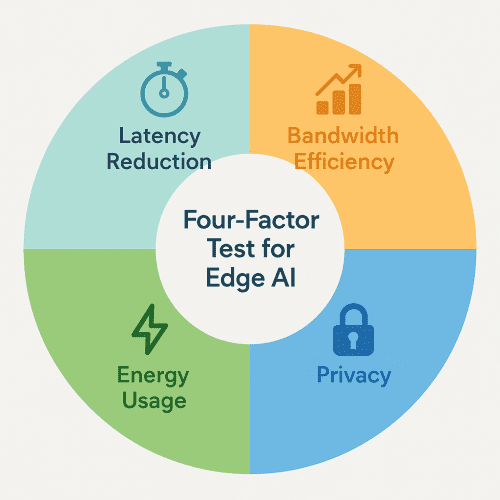
1. Latency & Real-Time Performance
Edge AI delivers sub-50 ms responses; Cloud AI adds 100–300 ms plus jitter.
2. Bandwidth Usage
Edge sends only insights; Cloud streams raw data.
3. Privacy & Compliance
Edge keeps data local, easing GDPR/HIPAA compliance. Federated learning enables collaborative model training without data sharing.
4. Cost & Maintenance
Cloud GPUs are pay-per-use but add up at scale. Edge requires hardware investment and OTA update pipelines.
Key Challenges & Mitigations
- Hardware Constraints: Optimise with pruning and quantisation to fit limited memory and compute.
- Security Risks: Implement secure boot, encryption, and tamper detection on edge devices.
- Update Management: Use OTA pipelines with versioning, rollback, and A/B testing strategies.
- Scalability: Leverage containerisation and orchestration (K3s, balena) for fleet management.
Future Trends in Edge AI
Emerging hardware like TinyML microcontrollers and neuromorphic chips will push inference to micro-watt scales. Advances in federated and split learning will further balance on-device privacy with centralised intelligence.
Real-World Examples
- Smart Retail: Jetson Orin shelf-scanning for instant restock alerts.
- Healthcare: Wearable ECG analysis for HIPAA-compliant arrhythmia detection.
- Industrial IoT: Raspberry Pi vibration analysis to predict failures without streaming raw data.
Quick Demo: Measuring Cloud Latency
import time, requests
HOST = "https://api.your-cloud-endpoint.com/infer"
start = time.perf_counter()
_ = requests.post(HOST, json={"data": "ping"}, timeout=5)
print(f"Round-trip latency: {(time.perf_counter()-start)*1000:.2f} ms")Ready to Master Edge AI Hands-On?
Enroll in our Edge AI: Deploying AI on Edge Devices course to learn model compression, TensorFlow Lite, ONNX Runtime and deployment on Raspberry Pi & Jetson.
Key Takeaways
- Edge AI is optimal for ultra-low latency and privacy.
- Cloud AI excels at scale and continuous updates.
- Hybrid architectures often deliver the best balance.
Frequently Asked Questions
Does Edge AI require expensive hardware?
No—optimisations allow inference on Raspberry Pi, Coral USB and even TinyML microcontrollers.
Is Cloud AI always more scalable?
Cloud is elastic, but managing millions of devices demands robust OTA pipelines—another scale challenge.